
Python快速下载网页并转为文本
作为一个程序员经常需要在网上查资料,但是不想在线看,有什么办法可以简单迅速的实现大量网页下载?这时Python作为一门简单易用的语言便可发挥作用了。
我们以下载新闻网站的新闻为例。
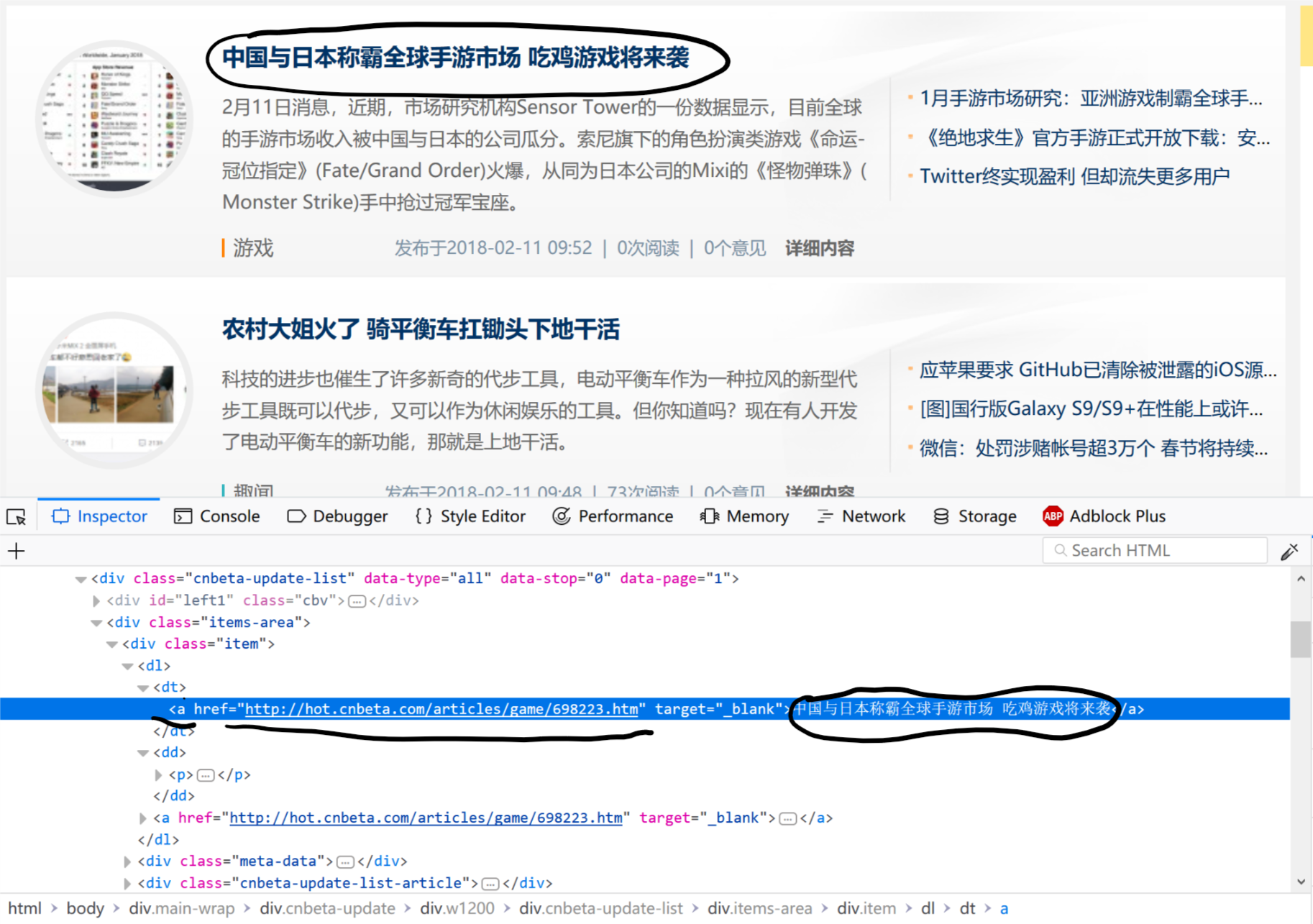
上图可以看到,”中国与日本称霸全球手游市场 吃鸡游戏将来袭”这条新闻对应的html元素为<a href="http://hot.cnbeta.com/articles/game/698223.htm" target="_blank">中国与日本称霸全球手游市场 吃鸡游戏将来袭</a>,对应的链接为a标签的href属性,也就是说只要获取到该标签的href属性的值便可得到该新闻的对应的链接。
下面我们来正式开始爬取内容。
以cofcool/COLTools项目的dhtml2text.py(python3)为例来说明。
1. 下载网页
python 3.3把urllib和urllib2合并为urllib,可通过Request来进行网络请求。self.__siteURL为爬取的网页地址。
def __get_page(self):
headers = {
'User': 'Agent: Mozilla / 5.0(X11;Ubuntu;Linux x86_64;rv: 57.0) Gecko / 20100101Firefox / 57.0',
'Accept': 'text / html, application / xhtml + xml, application / xml'
}
request = urllib.request.Request(self.__siteURL, headers=headers)
response = urllib.request.urlopen(request)
return response.read()
2. 提取a标签内容
下载完网页后,使用<a(.+?)href="(.+?)"正则来提取网页内的全部a标签,并放在self.__contents数组内。注意: 这种方法较为粗糙,如果要细致的提取,可根据爬取网站的html布局进行更细致的设置。
def __get_contents(self):
page = self.__get_page()
pattern = re.compile(b'<a(.+?)href="(.+?)"', re.S)
items = re.findall(pattern, page)
for item in items:
self.__contents.append(item[1])
return self.__contents
3. 批量下载提取到的链接
遍历提取到的a标签,并进行下载。
def __downloading(self):
contents = self.__get_contents()
for item in contents:
try:
self.__save_files(item.decode('utf-8'), item.decode('utf-8').split('/')[-1])
except UnicodeDecodeError as e:
self.__log_util.append(str(e))
self.__log_util.append('download successful!!!')
下载文件,有些网址可能没有域名,是相对路径,可一并处理为正常完整的网址,并根据链接提取网页的名称,下载保存。
def __save_files(self, file_url, filename):
file_path = self.__write_path + filename
if '.html' in file_url or '.htm' in file_url:
if 'http' not in file_url:
new_file_url = file_url
if '/' in file_url:
new_file_url = file_url.split('/')[-1]
if 'htm' in self.__siteURL:
last_slash_index = self.__siteURL.index(self.__siteURL.split('/')[-1])
file_url = self.__siteURL[0:last_slash_index] + new_file_url
else:
file_url = self.__siteURL + '/' + new_file_url
try:
u = urllib.request.urlopen(file_url)
data = u.read()
f = open(file_path, 'wb')
f.write(data)
f.close()
self.__log_util.append('the url is %s, write path is %s' % (file_url, file_path))
except(urllib.error.HTTPError, urllib.error.URLError, IOError) as e:
self.__log_util.append(str(e))
4. 转换html为文本内容
使用html2text进行文本提取,可通过pip3进行安装,pip3 install html2text。可把base_dir路径下的html文件转换为文本并合并到名为html2text.txt的txt文件中(combined参数设为True)。
class Html2Text:
def __init__(self, base_dir, combined, log_util):
self.__base_dir = base_dir
self.__contents = os.listdir(base_dir)
self.__contents.sort()
self.__combined = combined
self.__log_util = log_util
def export2text(self):
self.__log_util.append('start export')
combined_f = None
if self.__combined:
combined_f = open(self.__base_dir + '/' + 'html2text.txt', 'a')
for file_name in self.__contents:
self.__log_util.append('export %s' % file_name)
html_f = open(self.__base_dir + '/' + file_name, 'r')
html = html_f.read()
html_f.close()
clean_text = html2text.html2text(html)
combined_f.write(clean_text)
combined_f.close()
self.__log_util.append('finished!!!')
经过以上四步就可简单的下载想要看到的内容了,完整代码可在dhtml2text.py查看。